Languages of any kind are a two-edged sword. With the cooperative edge, you communicate. With the political edge, you control, using the utility of and dependence on communication to suit your interests. We who are involved in developing language processors and related tools can do well to keep these two edges in mind as we seek to add value with our work.
What is adding value
Clearly programming languages add value in terms of productivity. Even if we're fighting about the finer points of
static versus dynamic typing, or Perl vs. Python vs. Pure LISP, almost anything is better than the truly low level of pointing and grunting the computer uses. For most purposes today a FORTRAN or C compiler is better than an assembler.
I've been dwelling on the proposition
"programming languages as notation" (my wording) as summarized by
Tablizer thus:
Most of the CS literature fits the pattern found in a typical book or chapter on Boolean algebra. Generally this is the order and nature of the presentation:
- Givens - lay out base idioms or assumptions
- Play around with those idioms and assumptions to create a math or notation
- Show (somewhat) practical examples using the new notation or math
- Introduce or reference related or derived topics
Step 2 is where the value is added, and it boils down down to a "math or notation". In my experience with programming languages, I'd reinterpret that as meaning
- math: give a mapping from one semantic domain to another (direct language translation)
- notation: programming language syntax
With that as a working definition, we can see analytically how the first FORTRAN compiler added value. It gave programmers a more familiar notation (syntax) in that they could write expressions ("FORmulas") with infix arithmetic operators and it provided the math (mapping) from that syntax to the lower level assembly or machine language.
We've been getting lots of new languages since FORTRAN, C and LISP. Justifications for new languages have included these ideas, "
closing the semantic gap" between programmer and application. The hope is to achieve similar leaps of productivity as those initial leaps from the baseline of panel switches and card readers. It's the churn to gimme a better notation. The notation isn't the only thing of course, we want a decent mapping from the syntax to the semantic domain, to meet our performance requirements, and later, our software quality requirements: "let's eliminate whole categories of errors".
One curious result of the productivity leaps made by our newer languages is that they just make us want to write even bigger programs. We're not satisfied to write the old applications in an elegant, maintainable way using the new idioms and language features. We say "well,
now we can do that project we only dreamed of," and proceed to applications with ever-increasing scope. (An entertaining take on this can be found in the
Law of Leaky Abstractions).
With that said, I want to present a few ideas where language tools can be applied to the productivity challenge. These are opportunities for people with knowledge of compiler and interpreter internals but does not involve yet another new language. With acknowledgment of the irony in presenting these after just bemoaning application bloat, here are a few ideas for areas that could be improved in the practice of programming:
#1: Automatic refactoring support, like
Danny Dig's refactoring engine which is included in Eclipse 3.2. This helps make progress in the old can't-refactor-because-it's-not-backwards-compatible problem by providing automatic tools to upgrade client code when shipping libraries with changes in APIs.
#2: Code visualization - tools to understand the static structure and dynamic flow of code . We can also improve in historical visualization, or how code has changed between revisions.
#3: Data visualization - Debuggers let you examine and even edit data structures at runtime, why not provide similar capabilities at code writing time? Why not let programs be specified by something like Emacs record-and-play macros where you "edit" the data structures? I think part of what makes programming difficult because it's hard to automate something without seeing what's being automated. While
visual languages have not really taken off, I think it's an untapped potential, for some domains anyway.
#4: Automatic test generation - automatic creation of tests based on static inspection, to supplement hand-written tests.
#5: Machine-learning helpers for programming - instead of programming directly, use a tool that accepts examples of inputs and outputs and generates rules as starter code.
#6: Integration of coding environments with networked repositories - This means things like direct interfacing of language and tools help with team wikis to help share experience between programmers. Microsoft tools have started to do this, and there is room for growth. Instead of static coding style checkers definitions, what about augmenting them with networked information? Worse than Failure's
Code Snippet of the Day could be formally encoded to flag catch ridiculous code patterns immediately.
#7: Easier ways to search code by pattern, not just textually, but by structureThese tools don't need to apply to new languages. As we found with
AnnoDomini, a Y2K tool for fixing COBOL programs employing type theory and itself written using a functional language, tools can follow many years after their target language.
What adding value is not
We started by mentioning the two-edged sword of languages. The second side of languages, their use as a political tool, is not necessarily a way to add value, but it is to control. This phenomenon is studied in sociolinguistics, and you may have personal knowledge of it. What languages should be taught in schools? What languages can you get in trouble for speaking? What is the "official" language, or languages? What are the motivations for the proscribing or forbidding other people to use or not use a language?
While you think about that, let's talk about plugs and sockets. Let's say we make laptops. We will need to make a power supply, something that has two plugs. One is the AC side that plugs into the wall outlet using a standard connector. The other is the DC side that plugs into the laptop. For this DC connector, we have a choice of going standard, with an off-the-shelf standard size and shape, or going proprietary, designing a unique size and shape, possibly protected by patent. (For the record, I don't actually make laptop power supplies. So if they don't, for some reason, ever ever use standard connectors, I'd love to know, but I don't think it affects the analogy.) We can see the two edges of the language blade. As long as the DC plug and the laptops connector match, they cooperate, it works; the two side "communicate" power. The shape largely doesn't matter to the function of communication. But the choice of shape does affect what other laptops the power supply works with. By choosing a standard shape, we open the possibility of wider interconnectivity. By choosing proprietary, we restrict the possibilities. If someone needs a new power supply, now you have to come to us to buy it, or to a another vendor who licenses our connector patent.
The open vs. closed DC connector choice will sound like a familiar dichotomy from many technical fields, perhaps most familiar as the operating system question. I bring it up for the programming language audience as a reminder that any programming language represents a particular shape of interface, and we need to be aware of its potential for use as a political tool.
Back to human languages. We need to be aware of who is agitating for adoption of a language, and why they are doing it. Hear these motives with an ear for the programming language arena. "You may not use that language spoken by our enemies" emphasizes the enmity on a personal level. "You must now speak our language, vanquished foe" is part of a takeover plan. Language promotion can be sinister, as when members of an ethnic faction seek independence from a larger nation. They may appeal to ethnic identity as leverage to gain power, promoting the household ethnic language over the national one taught in schools. Language promotion need not be sinister. In an extremely fragmented situation it can achieve the communication productivity we spoke of before.
Papua New Guinea is actively promoting
Tok Pisin as a means of unifying its citizens who natively speak
thousands of quite different languages, a situation created in part by its poor network connectivity. No, that's not it, I mean by the rugged terrain and isolated mountain villages. You may see language promotion taking place, and wonder what the language itself does for people. But we need to look for the bigger picture, which includes understanding who is behind the promotion and what they are trying to achieve. "You must use this language because you belong to this group" plays up uniqueness of the group, as with Finnish. Modern Finnish was developed in the 19th century as part of a growing nationalism to help distinguish it from neighboring Sweden and Russia. The emphasis on uniqueness, of preserving culture is interesting. Cultural forms involving language include expressions, wise sayings, jokes, stories, songs and poetry. These form a body of useful works. Preserving them is valuable for those steeped in the culture. You could say they have a vested interest in the culture.
Among other reasons, I think one reason languages are given away for free by businesses is that it helps spread adoption of the interface, creating a hook to create business in other forms. Once a customer has paid to develop working code in a language, it represents a vested interest in that language. We can think of the vast collection of COBOL applications as the prime example.
New languages have had it tough. In the 80's and 90's, without an absolutely killer feature, such as infix expressions when the alternative is per line arithmetic, new languages were being developed, but perhaps not rapidly. I'd venture that new languages are only good for new projects and new people (called "youth"). The rise of the web has brought with it a slew of opportunities for both those factors to coexist, giving rising to a growth in the number of available languages to use both browser side and server side. As the web matures, I see companies still trying to take advantage of the momentum to adopt new languages (*cough* Adobe Flex *cough*), and while it's exciting I'm starting to see the other side. Is it really a boost in productivity if we're retooling our businesses and schools to use a new language and environment every few years? Or are we moving sandpiles around, taking the same basic program (no pun intended) from one person's vested interests to another? Be aware of the other edge of the language blade. Adopting or creating a new language may not be adding value. Or if it is, you need to know, adding value for whom?
For more reading:Cylindrical types of DC connectors at WikipediaLanguage politics at WikipediaCulture of Finland at Wikipedia
 Finally, the book opens with an illustration that partly addresses my question about bugs appearing in an implementation of a provably correct algorithm.
Finally, the book opens with an illustration that partly addresses my question about bugs appearing in an implementation of a provably correct algorithm. 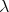 -strong reduction!
-strong reduction!